


I - Usage
I.1 - Syntax
The MATE translator recognizes two types of code blocks inside a C/C++ source file:
- (i) Sequential Blocks: These are sections of code that execute in a normal sequential order. By default, all code is treated as a Sequential Block unless it is enclosed by a MATE Graph pragma. Therefore, in a non-annotated source file, all the code blocks are considered sequential. The semantics of MPI functions remain unchanged in these blocks.
- (ii) MATE Graph Blocks: These are sections of code that execute in a data-dependency driven order. Inside a MATE Graph block the programmer defines regions that execute based on their dependencies, rather than the order in which they are placed. In fact, the positioning of regions inside the MATE block makes no difference in their execution order. MATE Graph blocks execute atomically. That is, when execution reaches a MATE Graph block, it executes completely before continuing with the next statement.
A programmer defines a MATE Graph block, its regions, and dependencies by using a set of #pragma directives. An example of annotation in MATE is shown below. In this case, the code is deterministic and the output will always be "abcdef".
The code shown above also illustrates the basic MATE syntax for defining a dependency graph. Annotation in MATE is defined by the use of only two pragma directives:
- #pragma mate graph
Defines a MATE graph block. Such block can be defined anywhere in the program, inside or outside a loop statement.
- #pragma mate region (X)
#pragma mate region (X) depends (Y)
#pragma mate region (X) depends (Y, Z)
Defines a named MATE region. The optional "depends" parameter defines which other regions(s) should be executed before the current region can be dispatched by the runtime. The first line defines a region "X" without dependencies which can be scheduled immediately. The second line defines a region "X" that will not execute until region "Y" has finished. Finally, the third line defines a region "X" that will not execute until regions "Y" and "Z" have finished.
Not all MATE Graph blocks execute deterministically. Consider, for example the following code:
The output of this program could be either "zxy" or "zyx". MATE does not offer any ordering guarantees when the graph is non-deterministic. There may be, however, a bias towards regions that are placed first. This obeys to the way the MATE Runtime System has been programmed, but not to any priority system as of yet. (Probably the best strategy will be Last-Ready-First, to improve cache locality).
Annotation in MATE is compute. That is, MATE will not assume default values or tolerate ambiguity in the annotation. In case the translator finds a syntax error, it halts and shows an error report including line content, line number, source file, and reason of error. A more detailed set of non-allowed annotations is shown below:
• MATE Graph blocks cannot be nested.
• MATE Regions cannot be defined outside MATE Graph blocks. (yet)
• Sequential code cannot be placed inside MATE Graph blocks. (yet)
• MPI Collectives cannot be located inside a MATE Region (yet).
I.2 - Dependencies
Each #pragma mate region directive represents a named code region. The programmer is free to define the name for each region using alphanumeric words. Examples of regions name could be: A, Receive, Compute, Produce, Consume, etc.
Each region in MATE defines a set of dependencies. In order for a region to be ready for execution, all its dependencies should be satisfied. There are two types of dependencies in MATE: compute and data.
Compute Dependencies
Compute dependencies are specified by the user as a parameter in #pragma mate region () depends (...) directive. The depends argument contains the name(s) of other region(s) upon which the current region depends.
In the code above we can see that the user has defined region X to depend on regions Y, and Z. This means that, until the code in regions Y and Z have executed completely, region X will not be scheduled for execution by the MATE Runtime System. The user is responsible for ensuring the program's original data-dependencies and correctness are still respected while defining compute dependencies.
Data Dependencies
Data dependencies are created automatically by MATE by detecting external wait events within a region. An external wait event is a blocking function call whose completion is determined by an external library. The list of external events considered by MATE is listed, but not limited, to the following:
- - Calls to MPI functions, such as: MPI_Irecv(), MPI_Isend, MPI_Recv, MPI_Send()...
- - Calls to cudaGetLastError(), cudaThreadSynchronize(), CudaMemCpy()...
(not yet implemented)
- - Calls to I/O functions.
(not yet implemented)
The MATE translator removes the blocking component of these procedures from the code, and replaces them by asynchronous versions programmed inside the MATE Runtime System. This transformation allows all regions to finish their execution non-preemptively. The asynchronous versions of those functions are processed as background operations while (ready) regions continue to be executed.
Unlike MATE, where data dependencies are detected in translation time and code is statically relocated based on them, the MATE translator only transforms them into asynchronous, leaving them in their original place. The MATE Runtime System registers those dependencies on runtime in the moment they are called. Not only this simplifies translation, but is also the key to allow generating complex dependency graphs.
When the MATE asynchronous functions are called, an data dependency is created and associated to its containing region. The dependency is then attached as a new dependency in all regions that have a compute dependency on the originating region. For example, if region X contains a MPI_Recv() call and region Z has a compute dependency on region X, the result is that Z will now have two dependencies: X and the result of MPI_Recv(). No region will be scheduled for execution until all its data and compute dependencies are satisfied.
Since external wait events are removed from their containing regions, the user must make sure that no intra-region data dependencies remain. In other words, there cannot be any data dependencies between clauses inside the same region. For example, the following code will produce erroneous results.
We can see in the code above that, since MATE translator transform MPI_Recv into an asynchronous call, use(data_x) will operate over incorrect or non-initialized data, producing an erroneous result or a program crash. The correct dependency graph in this example would be:
In the code above, a second region B is defined with a compute dependency on region A. Region B will not execute until both dependencies are satisfied:
- - (compute) Region A finishes executing.
- - (data) data_x is received and stored by the MATE Runtime System.
I.3 - For Loops
Using MATE Graph blocks inside for loops is allowed (Note: everything stated in this section also applies to while loops). For example, the following code is syntactically correct in MATE:
In the example, a MATE graph is defined inside a for-loop. Regions inside the graph will execute non-deterministically, with their order depending on the latency of the MPI Calls. Possible outcomes of this are shown, but not limited to, the list below:
- RL,CL,SL,RR,CR,SR, or:
- RR,CR,SR,RL,CL,SL, or:
- RL,RR,CL,CR,SR,SL, or:
- ... etc ...
However, it is important to note that the execution of regions is limited to those in the same iteration. We will use the following notation to denote that the region executes at a certain iteration: region_name(#iteration). For example, a possible execution of the previous example could continue like this:
- RL(0),RR(0),CL(0),CR(0),SR(0),SL(0), RR(1),RL(1),CR(1),CL(1),SL(1),SR(1)...
Since a MATE graph executes atomically, all their regions have to execute completely before exiting the block. This describes a dependency graph where the computations and communications for right need to wait for those of left to finish, and viceversa. The resulting data-dependency graph resulting from this notation is illustrated below:
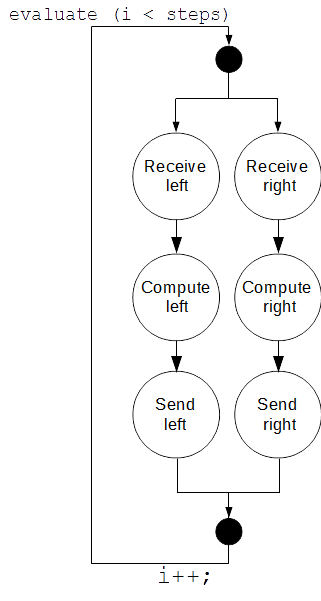
This graph clearly does not describe accurately the real dependency graph of this program, which is illustrated below:
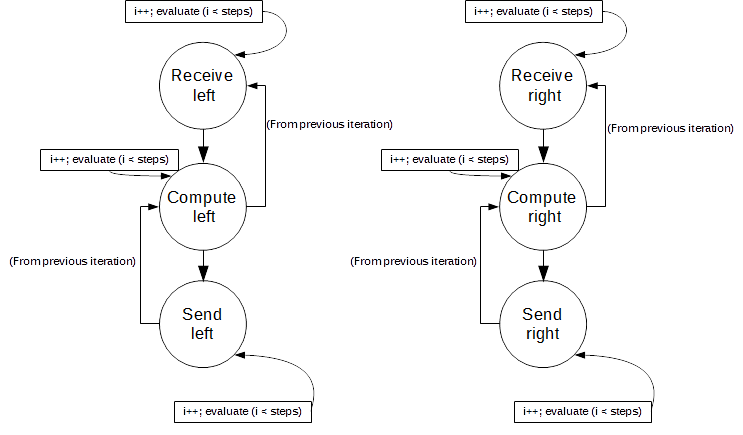
The dependency graph above shows that both right and left regions can execute concurrently and independently from each other. In fact, the execution of the receive regions depends only on the execution of their corresponding compute region in the previous iteration. We define this as a Cross-iteration Dependency. A possible outcome of hand-coding this program to reflect this new graph is shown below:
- RL(0),RR(0),CL(0),CR(0),RR(1),RL(1),SR(0),SL(0),CR(1),RR(2),CL(1),SR(1),SL(1),...
We can see that some operations can be executed with some iterations in advance, without compromising the correctness in the program, and maximizing internal overlap. To easily describe the graph shown above, MATE provides additional notations that can be used to define loop independent regions and cross-iteration dependencies:
#pragma mate graph for
Creates a new MATE Graph that is loop-aware. This pragma needs to be placed immediately before a for loop. The effect of using this pragma is that the associated for loop gets broken down into its containing regions. Each region executes with their own copy of the for declarations (e.g. int i = 0), evaluators (e.g. i < steps), and increments (i++).
Regions get assigned a step counter and both data and compute dependencies are created in a (region, step) basis. For a particular region/step pair (A, n) to be able to execute, the following conditions must be true:
- - All comute and data dependencies (B, m <= n) must have finished.
- - Loop evaluator must return true, otherwise the whole region is considered finished and removed from the scheduler.
#pragma mate region (A) depends (B*)
A cross-iteration dependency (annotated with the * symbol) behaves just like a normal dependency, except that it is ignored in the first iteration. This is necessary to break down the cyclic dependencies created when defining dependencies across iterations, starting on step 1 (as opposed to 0).
Anotating the previous example to generate the correct dependency graph with MATE using the new notation is very simple. The result is shown below:
We can see that, although the RL region depends on CL, it will be able to execute in the first iteration because CL was marked as a cross-iteration dependency which are initially satisfied.
Cross-iteration dependencies are a very useful way to optimize or develop wavefront algorithms, where some elements can advance further in the for loop while others are still waiting for communications.
I.4 - Graph Execution
In this section we explain how MATE schedules the regions within a task when it is executing in Graph Mode, that is: it has reached a MATE Graph block. In particular we explain step by step how regions and dependencies are created, executed, and removed.
As stated in the previous section, a task enters Graph Mode as soon as it reaches a #mate graph annotated block. At this point, the MATE Runtime System immediately creates compute dependencies while data dependencies are created dynamically, based on calls to blocking functions such as MPI point-to-point message send/receives.
As soon as blocking requests are satisfied, data dependencies are removed from the corresponding dependency vector(s). In turn, compute dependencies are satisfied by the non-preempted execution of dependended regions. As soon as a region's dependency vector is emptied, it is ready to execute.
When the task's region vector is emptied (that is, all regions have finished), it returns to execute sequentially in Normal Mode.
To illustrate MATE's Intra-task scheduling logic, we will simulate the execution of the following example graph block:
The step by step execution of the translated code is shown below:
0) Initial Step
At the very beginning of the graph block, the task does not have any region or dependencies registered. Therefore, it is still executing in normal mode.
|
|
||||||||||||||||||||||||||||||||||||||||||
1) Entering the MATE graph.
All the regions are created and set to T_READY state. Also, their dependency vectors are created empty.
|
|
||||||||||||||||||||||||||||||||||||||||||
2) After adding compute dependencies.
All the compute dependencies are created. We can see that 3 of the regions are set to T_WAIT state because they have unresolved dependencies in their dependency vector.
At this point, the runtime system will determine which of the two possible regions in T_READY state will execute next.
|
|
||||||||||||||||||||||||||||||||||||||||||
3) After calling MPI_Recv(data_x)
Now let's suppose that the recv_x is scheduled for execution (recv_y could have been selected as well). If we paused the execution right after MPI_Recv(data_x) has been called, but before the recv_x region finished, we would see how a new data dependency is created in compute1 and compute2 vectors:
|
|
||||||||||||||||||||||||||||||||||||||||||
3) After the recv_x region finishes.
After recv_x finishes finishes, the runtime system removes it from the task's region vector.
The compute dependencies on recv_x held by compute1 and compute2 are removed as well.
|
|
||||||||||||||||||||||||||||||||||||||||||
4) Repeating steps 2 and 3 with recv_y
Before scheduling the next region for execution, MATE checks if any pending external request(s) were satisfied. In this case, it will check if MPI_Recv(data_x) has finished. In this example we will assume that it has not finished yet.
Since the data_x data dependency is still not satisfied, the only region ready to execute is recv_y. MATE will schedule and execute it until it finishes, ending with the following state:
|
|
||||||||||||||||||||||||||||||||||||||||||
5) Task Preemption
We can see that all the regions are in T_WAIT state. When the task reaches this point, it will set its state to T_WAIT and yield execution so the MATE task can put another task in T_READY state to execute in the processor core.
6) After data_x Arrives.
Let's assume that, after some time, only the data_x request is satisfied. The MATE scheduler will detect that one of the task regions has satisfied all of its dependencies and set both the region and the task states to T_READY.
|
|
||||||||||||||||||||||||||||||||||||||||||
7) Task Resumes.
Since at least on of the regions is in T_READY state, the task is eventually scheduled for execution. The scheduler sets compute1 to compute this time and changes its state to T_EXEC:
|
|
||||||||||||||||||||||||||||||||||||||||||
8) compute1 finishes.
Once compute1 finishes executing, it is removed from the region list and all compute dependencies associated with it are removed. Let's now assume that the last external event data_y was satisfied while compute1 was executing. The compute2 region will now have no dependencies left and will be set to ready and scheduled for execution immediately without suspending the task.
|
|
||||||||||||||||||||||||||||||||||||||||||
9) send executes.
After compute2 finishes, the send region is ready to execute. After send finishes, there will be no regions left and the task is set back to normal mode. As we can see, all region and dependencies scheduling was handled dynamically and no traces of previous graph blocks should remain after their execution. The result of the execution is once again the empty state:
|
|
||||||||||||||||||||||||||||||||||||||||||
I.5 - Task Locality
We are currently developing an extension to the MATE API that allows developers gather information about task locality. This new API defines a locality hierarchy in which each task can be identified by Node and Process numbers. MATE's task locality API is shown below:
MATE's locality hierarchy distinguishes between three levels of locality: MPI, MATE global and MATE local:
MPI locality refers to the rank original decomposition provided by the MPI model. MPI_Comm_rank will return a unique identifier per task, while MPI_Comm_size will return the total number of tasks instantiated.
MATE Global locality refers to a process-wide granularity. Mate_global_process_id will indicate what MATE process id the calling rank belongs to. The same id will be returned for all tasks in the same MATE process. Mate_global_process_count will return the total number of MATE processes in the entire (multi-node) execution.
MATE Local locality refers to a task-wide granularity inside a MATE process. Mate_local_rank_id will indicate what the identifier of the calling task inside the MATE process. This id may be repeated in tasks in the other MATE process, but is unique in the current process. Mate_local_rank_count will return the total tasks inside the caller task's MATE processes.
Mate_isLocalNodeTask will indicate whether a task (MPI identifier) belongs to the same node as the calling task. Mate_isLocalProcessTask will indicate whether a task (MPI identifier) belongs to the same MATE process as the calling task.
void* Mate_Shared_Malloc(int key, size_t size); creates a memory allocation that is shared among all tasks in the same MATE process. Tasks calling this function using the same key will receive a local pointer to the shared allocation. The size of the allocation will that of the size variable used in the first call.
void Mate_LocalBarrier(); will suspend the exeucing task until all tasks in the same MATE process have reached that point.
Armed with these tools, a developer can easily establish the locality structure of the execution on runtime and allocate shared memory partitions for tasks living in the same MATE process to collaborate without the need of passing MPI messages. This approach enables efficient overdecomposition since the amount of intra-node/intra-process data motion due determined by the surface-to-volume ratio remains the same or can even be eliminated.