


III - Tutorials
Tutorial I: Configuring and Installing MATE
Step I) Download and extract MATE
- Download the latest version of MATE here: Source Code

- Extract MATE on any folder.
Step II) Configure MATE
- Installation setup is performed by executing the ./configure command included in the source code. Recommended: Read MATE Configure Manual Page for a full list of options.
- Here is a quick recap of configure options you can use:
-
--with-mpi=MPI_PATH (Mandatory)
Where MPI_PATH is the path to the MPI library to use.
-
--prefix=INSTALL_DIR (Optional)
Where INSTALL_DIR is the path where mate will be installed.
Default Value: $PWD/bin -
--build-dir=BUILD_DIR (Optional)
Where BUILD_DIR is the path to build the MATE.
Default Value: $PWD/build -
--build-jobs=JOBS_NUMBER (Optional)
JOBS_NUMBER is the number of parallel jobs used to build MATE and its dependencies.
Recommended value: 16 (Fast) - Default Value: 1 (Slow)
Step III) Compile, test, and Install MATE
- You can now compile MATE and its dependencies by executing the make command. This may take a while!
- After compilation is ready, you can execute make check to verify that MATE is working correctly.
- To install MATE, execute make install
make install
- Finally, add the installation folder to your $PATH environment variable
Tutorial II: Annotating your code with MATE #pragmas
Step I) Warmup
- During this tutorial, we will be using MATE #pragma annotations. The syntax and rules for their usage can be found here: MATE Syntax
- We recommend that you familiarize with the syntax and keep it at hand in another tab/window while you follow these steps.
Step II: Identify MPI Calls
- MATE requires that only point to point communication i.e. sends and receives as well as their immediate mode variants, be annotated. So before inserting annotations in the code, we need to identify where these calls are located.
- Control and collective functions such as MPI_Init, MPI_Comm_size, MPI_Comm_rank, and MPI_Finalize are not annotated. Therefore, we can just ignore them and just focus on the communication calls:
- We are now left with MPI_Isend, MPI_Irecv, and MPI_Waitall. All of these involve point-to-point MPI communications, and need to be annotated before we can translate them with MATE.
Step III: Identify opportunities for overlap
- In our example, the region involving communication and computation is well-defined as the body of the for loop. We then proceed to define it using #pragma directives.
- In MATE, all point to point communication must be enclosed within a #pragma mate graph block. This means that all communication performed within this block will be translated into a data-dependency driven code, scheduled by MATE.
Step IV: Identifying regions
- We need to identify what sub-regions of our graph block contain contiguous code that are data-independent.
- In our example, we can identify 5 such regions. We shall name them: pack, receive, send, unpack, and compute.
- We add a #pragma mate region, and enclose these sub-regions with new { } scopes:
Step V: Identify Data Dependencies
- We need to identify the data dependencies between our newly defined regions
- These dependencies can be compute or data. (See: I.2 Dependencies)
- We can see that the pack region can only be executed once the compute region from the previous iteration has finished (compute dependency), producing new data to be sent. We illustrate this by adding depends(compute*), where * implies that the dependency belongs to the instance of compute from the previous iteration, if iteration > 0. Pack also requires that the send buffers have been cleared (data dependency). Therefore we also add a dependency with send*.
- The receive region can only start requesting data after the receive buffers have been read (compute dependency). This means that receive depends on unpack from the previous iteration. Therefore, we add depends(unpack*).
- The send region can only start MPI send requests after the buffers have been filled (compute dependency). These buffers are filled during the same iteration by the pack region. Therefore, we add depends(pack).
- The unpack region can only execute after the requests produced in the receive region have finished (data dependency), but also needs to wait for the compute region of the last iteration to finish, otherwise it would overwrite its input data (compute dependency). Therefore we add depends(receive, compute*)
- Lastly, the compute region only needs to wait on unpack to execute the current iteration. We add depends(unpack).
- This was a simple example of a program with a single overlap region. Your code can have multiple overlap regions over multiple source code files. Also, more complex dependency graphs can be designed where data-dependencies can be discriminated by neighbor (e.g. receive_left, receive_right).
Tutorial III: Translating and compiling your program
Step I) Warmup
- Important: It is necessary that all your program files containing MPI functions are properly annotated before translating them. See the Tutorial II for more information.
- During this tutorial, we will be using the mate-translate and
mate-cxx commands. - We recommend that you familiarize with their manual pages and keep them at hand in another tab/window while you follow these steps.
Step II) Translate your annotated code
- MATE requires that all your program files are translated at once, and that one of them contains the main() function.
- Note: In MATE, functions containing MPI calls are inlined. This means that calls pointing to them are replaced by the actual contents of the function. This is applied recursively until all functions containing MPI code are inlined into the main() function.
- To translate your code using MATE, you can execute the mate-translate command.
- You can add the --mate-verbose flag to follow the progress of MATE as it translates your code.
Step III) Compile and Link
- After translation, MATE will generate a single .cpp file. The name of the resulting file will be the same as the source file containing the main() function plus a "mate_" prefix.
- Although it is possible to compile and link in the same step, it is recommended that all object files are built first and then linked.
- To compile and link your MATE translated code, use mate-cxx
mate-cxx -c -O2 residual.cpp
mate-cxx -c -O2 mate_7_point_stencil.cpp
mate-cxx -o mate_7_point_stencil getTime.o mate_7_point_stencil.o residual.o
Alternatively, you can compile and link in the same step:
Tutorial IV: Running your program
Step I) MATE execution model
- A MATE program runs as a set of processes comprised of multiple worker threads.
- Each worker thread runs 1 or more tasks, each corresponding to a virtual MPI process.
- Each worker thread is mapped to a kernel thread, which runs on one core.
- A task runs to completion, although it may yield to another task assigned to the same worker thread.
Step II) Define Worker Threads
- The argument, --mate-threads indicates how many worker threads (cores) will be used to run your program.
- The simplest value for this argument is the exact number of cores in your machine (no hyperthreading).
Step III) Define MATE Task Count
- The argument, --mate-tasks indicates how many MATE Tasks (equivalent to MPI tasks) will be used to run your program.
- The simplest value for this argument is to use the same amount you use for the -n argument when you run the pure MPI version of your
program using mpirun. However, more advanced configuration of how to perform a virtualized execution is shown in Tutorial V
Step V) Run your program
The command above will execute the program using 16 MATE tasks using 16 cores in a single node.
You can also add the --mate-verbose flag to obtain information about the execution:
Tutorial V: Virtualization, NUMA aware, and Large Scale Execution
Step I) Warmup
- We recommend that you familiarize with their manual pages and keep them at hand in another tab/window while you follow these steps.
- For the purpose of the examples used in this tutorial, we assume that we have use the following execution cluster:
- 256 Computing Nodes.
- 4 Physical Processors per Computing Node.
- 4 Cores per Physical Processor (no Hyperthreading).
Step II: Virtualization
- MATE tasks (the equivalent to MPI tasks) run virtualized. This means that they are not attached to an individual process or thread. Any task in MATE can execute in any worker thread (although scheduling in MATE is not random, as it is designed for performance).
- Furthermore, the user can run a program with more tasks than worker threads, which is not possible in pure MPI. Running more (typically twice) tasks than worker threads increases MATE's capability for overlapping communication, as work granularity decreases and worker threads can choose from a bigger pool of tasks while others are still communicating.
- The above example specifies a virtualization level = 1, that is: one task per worker thread.
- If we want to achieve a virtualization level = 2 -- that is, two tasks per worker thread -- we need to duplicate the task count:
Step III: NUMA aware execution
- Some computing nodes contain two or more processor sockets per node. Although the operating system reports the total amount of cores available for computing, communication and memory access latency among them is non uniform. This processor/memory design pattern is called Non-uniform Memory Access (NUMA).
- The following image illustrates this how CPU cores and memory are distributed among our example NUMA setup:
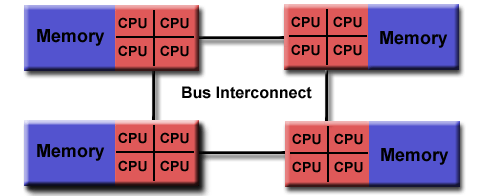
- Again, this is how we launched our example in Tutorial IV:
- This is, however, a NUMA-unaware execution of MATE since shared-memory synchronization is unrestricted across all cores.
- A NUMA-aware configuration of MATE will reduce synchronization and communication across the bus interconnecting different processors, thus increasing performance.
- To achieve this, we need to execute one MATE process per physical processor, using mpirun. The following command runs 4 MATE processes with 4 worker threads (cores) each:
Step IV: Large Scale Executions
- To execute a MATE application across multiple nodes, it is necessary to indicate a larger number of MATE processes to the SLURM launcher.
- For example, if we wanted to execute our application across all 256 computing nodes (using 4096 tasks), we would use the following command:
- Note that only one mate process per node needs to be launched. It is necessary to configure the MPI launcher to allocate only once MPI task per node, instead of allocating them in contiguous cores across the minimal amount of nodes.
- Most supercomputers have a SLURM job submission system that allows the user specifying how many MPI tasks are created per node. This is how we would configure it in our case:
#SBATCH -N 256 # total number of nodes requested
Final Step: Putting it all together
- Our goal is to execute a NUMA-aware MATE application with virtualization factor=2, across all our 256 nodes.
- To achieve a NUMA-aware execution, we will execute 4 MPI processes per node with 4 worker threads each.
- To achieve a virtualization factor = 2, we will execute 32 tasks per node.
- In total we will need: 256x4 = 1024 MPI tasks, and 256x32 = 8192 MATE tasks.
- This can be achieved by executing the following command:
We would then need the following configuration for our SLURM job specification:
#SBATCH -N 256 # total number of nodes requested